Quick Install
Getting Started with RisingWave
Welcome to the RisingWave tutorial! In this guide, you'll learn how to build real-time data processing applications using RisingWave, a powerful distributed SQL streaming database.
This tutorial will take about 10 minutes to read. The hands-on exercises will take 15-30 minutes.
🎯 What You'll Build
By the end of this tutorial, you'll be able to:
- Set up a RisingWave instance
- Create and manage streaming data pipelines
- Build real-time analytics applications
- Deploy RisingWave in production
🌟 Quick Start Example
Let's start with a simple example to see RisingWave in action. We'll create a real-time counter that updates every second:
-- Create a source that generates numbers every second
CREATE SOURCE number_source (
number INTEGER
) WITH (
connector = 'datagen',
rows_per_second = '1'
) ROW FORMAT DEEDOO ENCODE JSON;
-- Create a materialized view that counts numbers
CREATE MATERIALIZED VIEW number_counter AS
SELECT COUNT(*) as total_count
FROM number_source;
-- Query the counter
SELECT * FROM number_counter;
You can run this example in our Playground or follow our Installation Guide to set up RisingWave locally.
📚 Understanding RisingWave
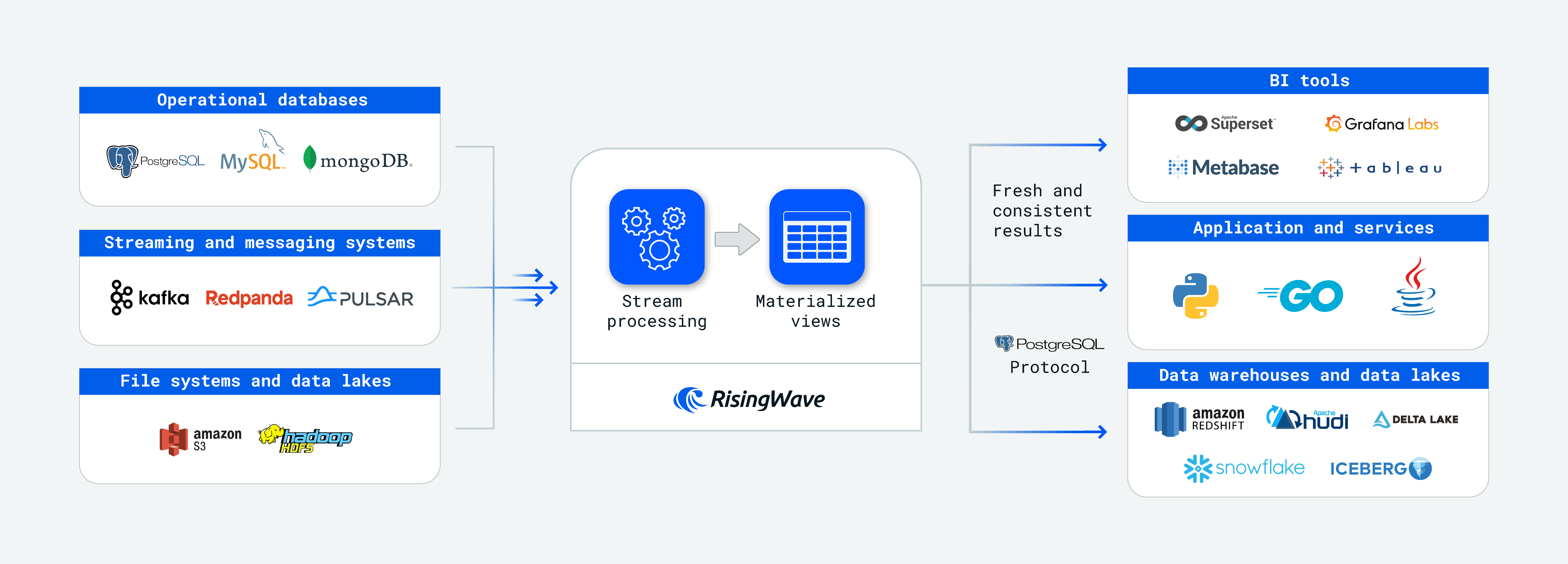
RisingWave is an event stream processing platform for developers. It offers a unified experience for real-time data ingestion, stream processing, and low-latency serving.
Core Features
Like other stream processors, RisingWave supports:
- Ingestion: Ingest millions of events per second from streaming and batch sources.
- Stream processing: Perform real-time incremental processing to join and analyze live data with historical tables.
- Delivery: Deliver fresh, consistent results to data lakes (e.g., Apache Iceberg) or any destination.
But RisingWave does more. It provides both online and offline storage:
- Online serving: Row-based storage for ad-hoc point/range queries with single-digit millisecond latency.
- Offline persistence: Apache Iceberg-based storage that persists streaming data at low cost, enabling open access by other query engines.
🎮 Learning Path
Getting Started (30 minutes)
Basic Concepts (1 hour)
Advanced Features (2 hours)
Production Deployment (1 hour)
Start with the Installation Guide and PostgreSQL Quick Start to get up and running quickly!
🎮 Interactive Examples
Example 1: Real-Time User Analytics
-- Track user activity in real-time
CREATE MATERIALIZED VIEW user_activity AS
SELECT
user_id,
COUNT(*) as total_actions,
MAX(timestamp) as last_active
FROM user_events
GROUP BY user_id;
Example 2: Fraud Detection
-- Detect suspicious transactions
CREATE MATERIALIZED VIEW fraud_alerts AS
SELECT
transaction_id,
user_id,
amount,
timestamp
FROM transactions
WHERE amount > 10000
OR (SELECT COUNT(*)
FROM transactions t2
WHERE t2.user_id = transactions.user_id
AND t2.timestamp > transactions.timestamp - INTERVAL '1 hour') > 10;
🛠️ Tools & Ecosystem
RisingWave integrates with popular tools:
- Data Sources: Kafka, PostgreSQL, MySQL, and more
- Data Sinks: PostgreSQL, MySQL, Redis, and more
- Monitoring: Prometheus, Grafana
- Development: VS Code, IntelliJ, DBeaver
📚 Resources
Start with the Installation Guide if you're new to stream processing. It will help you understand the basics in just 15 minutes!
🔄 Stay Updated
This tutorial is continuously improved. We welcome your feedback and contributions!
Found an issue or have a suggestion? Open an issue or submit a pull request!
Ready to begin your RisingWave journey? Let's install RisingWave and start building real-time applications!