Data Ingestion
In databases, users often use the insert statement to input data. However, in stream processing, data is continuously imported from upstream systems, and evidently, the insert statement is unable to meet this need. RisingWave allows users to directly create table and source to import upstream data. When there is new data entering from the upstream systems, RisingWave will directly consume the data and carry out incremental computations.
Common upstream data source systems for RisingWave include:
- Messaging systems, such as Apache Kafka, Apache Pulsar, Redpanda, and so on;
- Operational databases, like MySQL, PostgreSQL, MongoDB, and so on;
- Storage systems, like AWS S3, and so on.
Readers can refer to the official documentation to understand all supported data sources.
table and source
In RisingWave, users can use the following statements to create table or source, thereby establishing a connection with upstream systems.
CREATE {TABLE | SOURCE} source_or_table_name
[optional_schema_definition]
WITH (
connector='kafka',
connector_parameter='value', ...
)
...
After creating a table or source, RisingWave will continuously consume data from the upstream system.
| Functionalities | table | source |
|---|---|---|
| Support persisting data | yes | no |
| Support primary key | yes | no |
| Support appending data | yes | yes |
| Support updating/deleting data | yes, but a primary key needs to be defined | no |
A very fundamental difference between table and source is that table will persist the consumed data, while source will not.
For instance, if the upstream inputs 5 records: AA BB CC DD EE, if using table, these 5 records will be persisted within RisingWave; if using source, these records will not be persisted.
The following image illustrates the logic of creating a table in RisingWave.
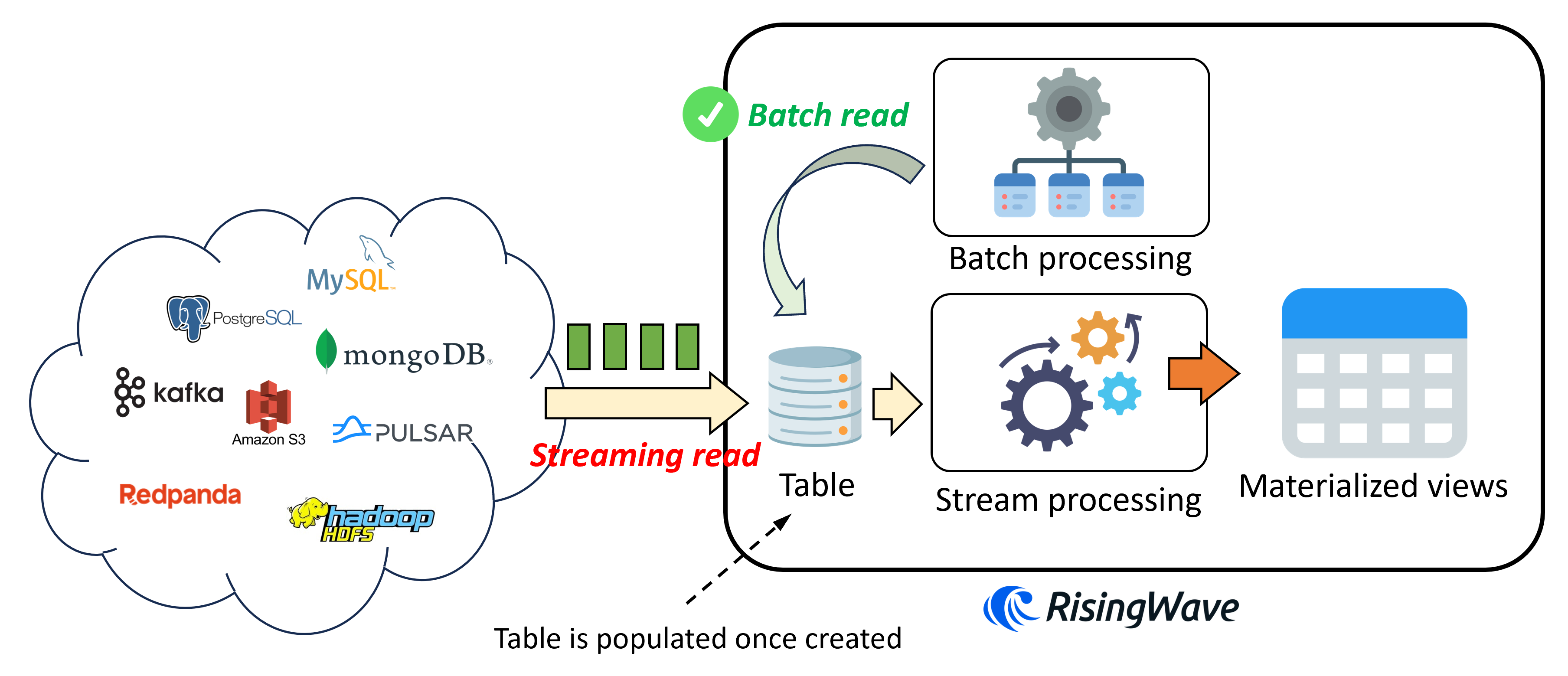
Here are a few key points worth noting:
- When a user sends a
create tablerequest, the corresponding table will be immediately created and populated with data. - When a user creates a materialized view on the existing table, RisingWave will start reading data from the table and perform streaming computation.
- RisingWave's batch processing engine supports direct batch reading of the table. Users can send ad-hoc queries to directly access the data within the table.
The significant advantage of using tables to persist records is that it can speed up queries. Naturally, if the data is within the same system, queries will be much more efficient, although the downside is that it occupies storage. Another advantage is the ability to consume data changes. That is to say, if the upstream system deletes or updates a record, this operation will be consumed by RisingWave, thereby modifying the results of the stream computation. On the other hand, source only supports appending records and cannot handle data changes. To allow table to accept data changes, a primary key must be specified on the table.
The following image illustrates the logic of creating a source in RisingWave.
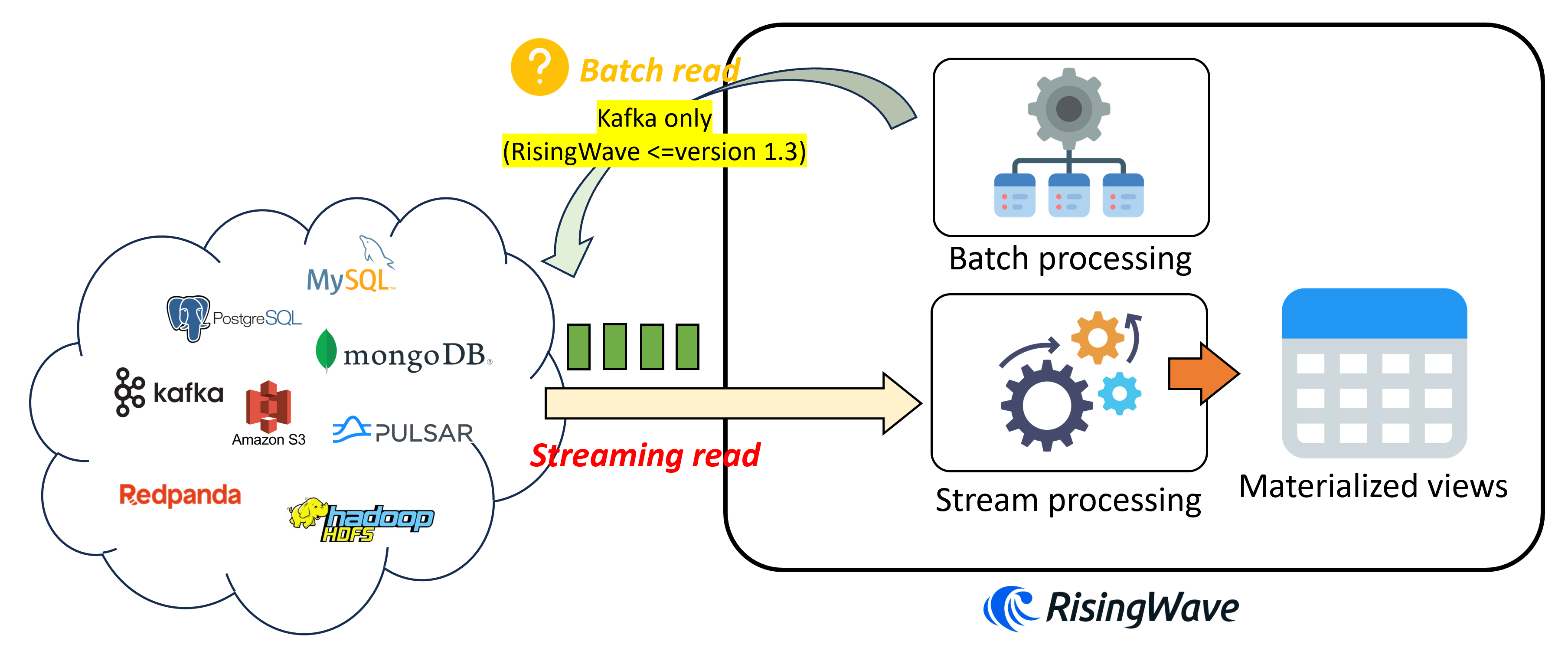
Here are a few important points to note:
- When a user sends a
create sourcerequest, no physical objects are created, and data is not immediately read from the source. - Data from the source is only read when a user creates materialized views or sinks on that source.
- In RisingWave version 1.3 (and earlier), the batch processing engine only supports batch reading from Kafka sources. When users send random queries to access the source, exceptions will be raised.
Some users do not want to persist data in RisingWave. However, if the data is not persisted in RisingWave, RisingWave cannot obtain ownership of the data. If random querying of source data is supported, it means that RisingWave is required to directly read the data stored in the upstream system. This cross-system data read is likely to cause data inconsistency issues, as RisingWave cannot determine whether there are other users in the upstream system who are writing data concurrently. Furthermore, frequent cross-system access can cause a significant drop in system performance. To ensure consistency and performance, RisingWave's initial design does not support random querying of source.
Of course, as you may have seen, some databases, like PostgreSQL (requires plugin), support random access to external data sources. Based on users' requests, RisingWave has supported querying data directly from Kafka source. More systems may be supported in the future, based on the user requests. If you need this feature, you are welcome to propose and discuss it with us on the roadmap page.
Sample Code
Now let's quickly verify RisingWave's data import capability. Since RisingWave trial mode does not support database CDC (at least Docker deployment mode is required), it's more suitable to choose Apache Kafka as the upstream message source. If you don't have Kafka, that's not a problem, we can directly use RisingWave's built-in datagen tool for simulation.
Ingest data
We will create a table and a source separately, and use the datagen tool to ingest data:
CREATE TABLE t1 (v1 int, v2 int)
WITH (
connector = 'datagen',
fields.v1.kind = 'sequence',
fields.v1.start = '1',
fields.v2.kind = 'random',
fields.v2.min = '-10',
fields.v2.max = '10',
fields.v2.seed = '1',
datagen.rows.per.second = '10'
) ROW FORMAT JSON;
CREATE SOURCE s1 (w1 int, w2 int)
WITH (
connector = 'datagen',
fields.w1.kind = 'sequence',
fields.w1.start = '1',
fields.w2.kind = 'random',
fields.w2.min = '-10',
fields.w2.max = '10',
fields.w2.seed = '1',
datagen.rows.per.second = '10'
) ROW FORMAT JSON;
Let's verify whether the creation was successful:
show tables;
We should get:
Name
------
t1
(1 row)
show sources;
We should get:
Name
------
s1
(1 row)
Note that if we use the PostgreSQL shortcut command \d, we will only see t1 and not s1. This is because source is not a relation as defined by PostgreSQL. To ensure compatibility with various PostgreSQL tools, RisingWave does not display source as a relation.
After creating t1 and s1 for a while, we use the select statement to query t1 and s1:
select count(*) from t1;
Received results (the exact number may vary):
count
-------
8780
(1 row)
If we run:
select count(*) from s1;
Received results:
ERROR: QueryError: Scheduler error: Unsupported to query directly from this source
This result is as expected. Because in RisingWave, users cannot directly query a source (unless it's from Kafka).
Stream processing in action
Then let's start creating materialized views for stream processing. We create materialized views on top of t1 and s1:
create materialized view mv_t1 as select count(*) from t1;
create materialized view mv_s1 as select count(*) from s1;
We then run:
select * from mv_t1;
Received results (the exact number may vary):
count
-------
12590
(1 row)
We run:
select * from mv_s1;
Received results (the exact number may vary):
count
-------
320
(1 row)
You might be surprised by the results: even though mv_t1 and mv_s1 were created almost at the same time, and the data in t1 and s1 is similar, why are the results significantly different?
The reason is that when the table is created, RisingWave starts consuming data from upstream and persists it internally. If a materialized view is created on the table at any time, the new materialized view will start reading from the oldest data in the table and perform stream computation. On the other hand, when the source is created, RisingWave does not immediately consume data from upstream. It's only when a materialized view is created on that source that RisingWave begins to consume data from the corresponding upstream source.
Returning to the example, the moment t1 is created, RisingWave starts consuming data from upstream (which is the datagen corresponding to t1) and persists it in t1. When mv_t1 is created, RisingWave reads the data already saved in t1 and continues to consume data from datagen. However, when s1 is created, RisingWave does not immediately consume data. It's only when mv_s1 is created that RisingWave starts consuming upstream data. Hence, we see different results.
Continue reading
Connector - Source: Learn more about the specific connection methods and configurable items for different upstream systems.