Fun Questions
Upon first learning RisingWave, readers from different backgrounds often ask many interesting questions. In this article, we summarize some common questions.
Can RisingWave replace Flink SQL?
RisingWave is a superset of Flink SQL in terms of capabilities. Users of Flink SQL can easily migrate to RisingWave. However, RisingWave also offers additional features that are not present in Flink SQL, such as cascading materialized views.

RisingWave uses PostgreSQL syntax, which lowers the learning curve and makes it more accessible compared to Flink SQL. However, it's important to note that there are still some minor syntax differences between RisingWave and Flink SQL, so users may need to modify certain queries.
Is RisingWave a unified batch and streaming system?
The term "unified batch and streaming" was initially used to describe computing platforms like Apache Spark and Apache Flink, rather than databases. But if we apply this concept to databases, then stream processing refers to the continuous incremental computation on newly inserted data, while batch processing refers to batch computation on already stored data. RisingWave clearly supports both stream processing and batch processing.
It is important to note that RisingWave excels in stream processing. In terms of storage format, since RisingWave adopts a row-based storage, it is more suitable for point queries on stored data rather than full table scans. Therefore, if users have a significant need for ad-hoc full-table analytical queries, we recommend using OLAP databases like ClickHouse or Apache Pinot.
Does RisingWave support transaction processing?
RisingWave does not support read-write transaction processing, but it does support read-only transactions. RisingWave cannot replace PostgreSQL for transaction processing. This design choice is primarily because in real-world scenarios, users generally require the use of dedicated transactional databases to support online business operations. Supporting both transaction processing and stream processing within the same database would make the workload management extremely complex and it would be difficult to optimize for both aspects.
In production, the best practice for using RisingWave is to place it downstream from the transactional database. RisingWave reads serialized data from the transactional database using change data capture (CDC).
Why does RisingWave use row-based storage for tables?
RisingWave utilizes the same storage system to support internal state management and data storage. For internal state management, row-based storage is more suitable for storing various types of operators. In data storage, since users are more likely to perform ad-hoc point queries, row-based storage is also more appropriate. In the future, RisingWave may periodically transform row-based storage into columnar storage to better support ad-hoc analytical queries.
Can a stream database be considered as a combination of a stream processing engine and a database?
A stream database is not simply a concatenation of a stream processing engine (such as Apache Flink) and a database (such as PostgreSQL). The main reasons include:
- From a design perspective, a stream database uses the same storage system for internal state management, result storage, and random result queries. An independent database is clearly not suitable for internal state storage because frequent cross-system data access would incur significant overhead, which is not desirable for stream processing systems that are latency-sensitive. In fact, earlier distributed stream processing engines like Apache Storm and Apache S4 attempted this approach, but it was not successful in the long run.
- From a functional perspective, one of the core features of a stream database is cascading materialized views. To simulate cascading materialized views, users would need to introduce additional components like Kafka message queues outside of the stream processing engine and database to facilitate message passing between materialized views.
- From an implementation perspective, ensuring consistency across multiple independent systems requires establishing a framework that ensures consistency even in the event of a system failure. Implementing such a framework requires significant engineering effort.
- From an operational perspective, managing multiple independent systems would incur high operational costs.
- From a user experience perspective, there is a significant difference between using multiple systems and using a single integrated system.
What's the difference between streaming databases and real-time OLAP databases?
Mainstream streaming databases include RisingWave, KsqlDB, etc., while mainstream real-time OLAP databases include ClickHouse, Apache Pinot, etc.
In terms of use scenarios, stream databases are mainly used for monitoring, alerting, real-time dashboards, and similar business purposes. OLAP databases are primarily used for interactive reporting and similar business purposes. Additionally, stream databases are also used for streaming ETL operations.
In terms of functionality, both stream databases and OLAP databases support predefined queries through materialized views and can also handle ad-hoc queries. However, stream databases excel in supporting predefined queries, while OLAP databases excel in handling ad-hoc queries.
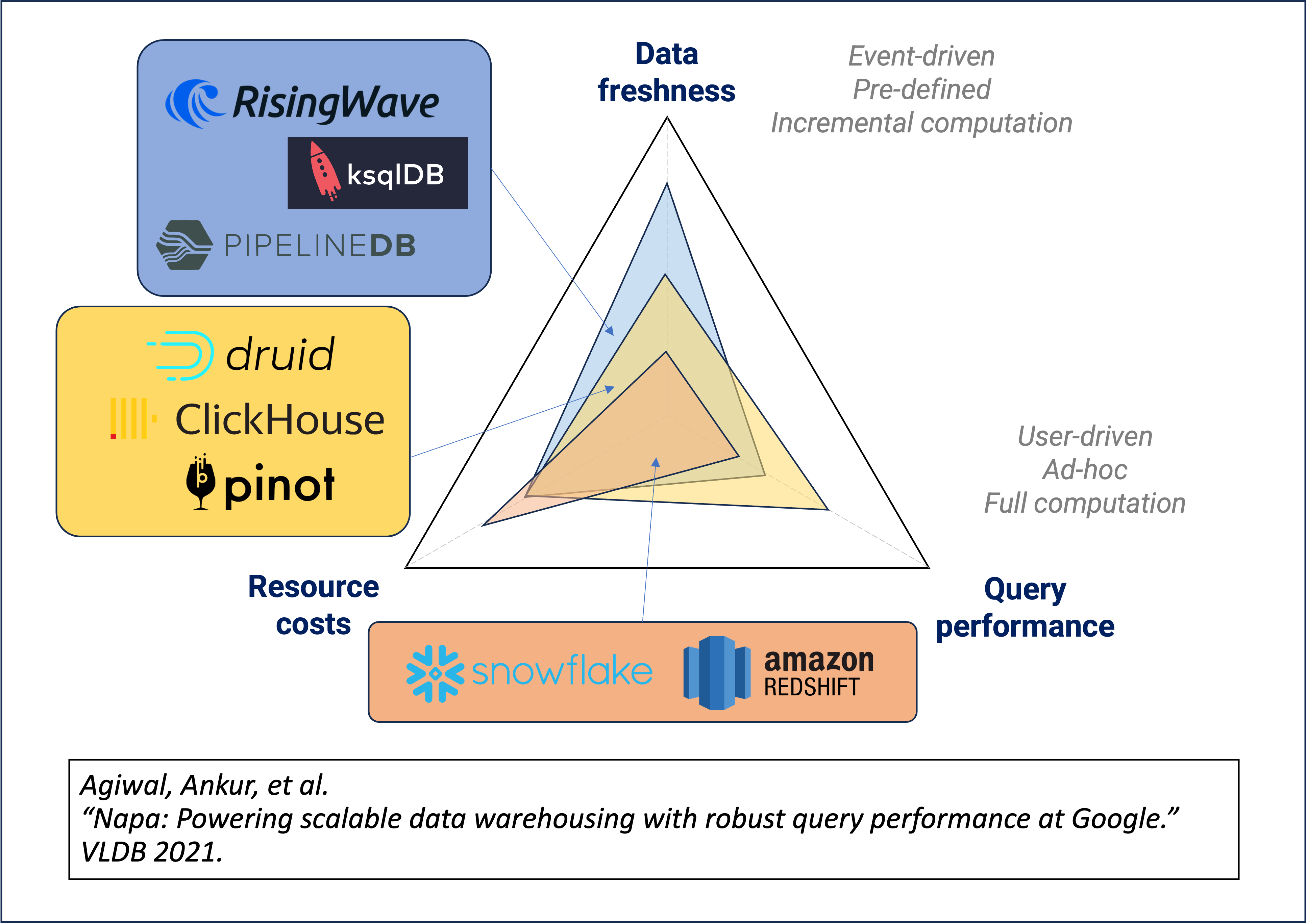
In terms of design, stream databases and OLAP databases optimize for different aspects. In the Napa paper, Google engineers proposed the system's trade-off triangle, which states that any system can only optimize two out of the three aspects: freshness of results, performance of ad-hoc queries, and resource costs. It is not possible to optimize all aspects simultaneously.
Assuming fixed resource costs, stream databases inherently optimize for result freshness, while OLAP databases optimize for the performance of ad-hoc queries. The following diagram illustrates the design trade-offs between stream databases, OLAP databases, and data warehouses.
How are the materialized views in streaming databases different from those in OLAP databases?
Due to the different focuses of stream databases and OLAP databases, although their materialized views may seem similar, there are significant differences between them.
In stream databases like RisingWave, materialized views are a core capability. Materialized views in stream databases need to present consistent and up-to-date computation results after stream processing. On the other hand, in OLAP databases like ClickHouse, materialized views are a supplemental capability. OLAP databases often update materialized views using a "best effort" approach. Additionally, materialized views in stream databases implement various advanced semantics of stream processing.
In summary, materialized views in stream databases like RisingWave have the following important characteristics:
Real-time: Many databases update materialized views asynchronously or require manual updates by users. However, materialized views in RisingWave are updated synchronously, ensuring users always query the freshest results. Even for complex queries involving joins and windowing, RisingWave efficiently handles synchronous processing to maintain the freshness of materialized views.
Consistency: Some databases only provide eventually consistent materialized views, meaning the results on materialized views are approximate or contain errors. Especially when users create multiple materialized views with different refresh strategies, it becomes challenging to see consistent results across materialized views. Materialized views in RisingWave are consistent, ensuring that users always see correct results even when accessing multiple materialized views.
High availability: RisingWave persists materialized views and implements frequent checkpoints for fast failure recovery. When a physical node running RisingWave experiences a failure, RisingWave achieves recovery within seconds and updates the calculation results to the latest state in seconds.
High concurrency: RisingWave supports high-concurrency ad-hoc queries. Since RisingWave persistently stores data in remote object storage in real-time, users can dynamically configure the number of query nodes based on the workload, effectively supporting business requirements.
Stream processing semantics: In stream processing, users can apply high-level syntax such as time windows and watermarks to process data streams. Traditional databases do not have these semantics, so users often rely on external systems to handle these semantics. RisingWave is a stream processing system that comes with various complex stream processing semantics, allowing users to operate on data streams using SQL statements.
Resource isolation: Materialized views involve continuous stream computation and consume a significant amount of computing resources. To avoid interference between materialized view computations and other computations, some users transfer the materialized view functionality from OLTP or OLAP databases to RisingWave, achieving resource isolation.